
Introduction
Overfitting is a pervasive problem in machine learning, often leading to overly optimistic estimates of performance on unseen test examples. In this article, we will explore two common cases of overfitting: including information from a test set in training and overusing a validation set.
Overfitting: A Primary Problem in Machine Learning
Imagine a classroom where the teacher announces a test, but instead of giving away the questions, they allow students to draw random questions until they find one they like. This is an analogy for overfitting the validation set, a common mistake in machine learning.
We will also discuss the more insidious form of overfitting: including information from a test set in training. This can occur when a model is trained on a dataset that includes information from the test set, leading to biased estimates of performance.
Overfitting Validation Set
When you try various settings and compare them using the same validation set, you may find a configuration with a good score. However, this is not a reliable way to evaluate your model’s performance, as it can lead to overfitting.
There is a paper on this topic: “Generalization in Adaptive Data Analysis and Holdout Reuse” by Andrew Gelman. This paper discusses the problem of overfitting the validation set and provides a solution.
Examples of Overfitting
In finance, overfitting can occur when backtesting a model using historical time series data. This can lead to biased estimates of performance and poor results in the future.
In statistics, overfitting is known as p-value hacking. This occurs when a scientist tries various experiments until they find one with statistical significance, as measured by the p-value.
R package emo
Overfitting can also occur in TV sports commentary, where pundits have access to various statistic trivia. If you watch sports, you have likely heard commentators make claims that are based on small sample sizes or biased data.

Sports journalists must have p-hacking tools that put scientists to shame. Source: @talyarkoni
Finally, some plots. It is plain to see that the relation between these two cannot be a coincidence:
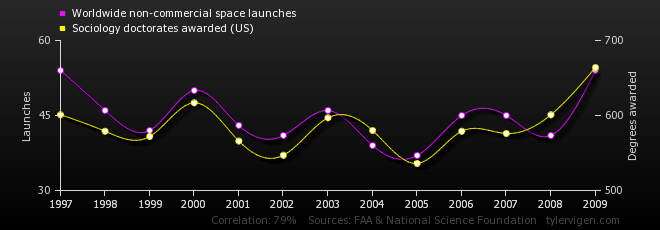
If you live in Maine, USA, and you want your marriage to last, be very wary of margarine:

Source: Spurious correlations
Overfit Automatically
Things get worse when you automate trying different configurations, as in hyperparameter tuning. Especially with a random or grid search. The “intelligent” variants, for example Bayesian methods, zero in on regions of search space which seem to be consistently good. This reduces the problem.
Random search hops all over the board, and the longer it runs, the more probable it is to find a spurious lucky configuration. We’ve witnessed it firsthand with Hyperband. So maybe curb your enthusiasm for random hyperparam search.
For more ways to overfit, see “Clever Methods of Overfitting” by John Langford (2005!).
Conclusion
In conclusion, overfitting is a pervasive problem in machine learning that can lead to biased estimates of performance. It is essential to be aware of the common cases of overfitting and take steps to prevent it. By understanding the causes and consequences of overfitting, we can build more reliable and accurate machine learning models.
Frequently Asked Questions
Question 1: What is overfitting?
Overfitting is a problem in machine learning where a model is too complex and performs well on the training data but poorly on new, unseen data.
Question 2: What are the common cases of overfitting?
The two common cases of overfitting are including information from a test set in training and overusing a validation set.
Question 3: How can overfitting occur in finance?
Overfitting can occur in finance when backtesting a model using historical time series data. This can lead to biased estimates of performance and poor results in the future.
Question 4: What is p-value hacking?
P-value hacking is a form of overfitting in statistics where a scientist tries various experiments until they find one with statistical significance, as measured by the p-value.
Question 5: How can overfitting be prevented?
Overfitting can be prevented by using techniques such as regularization, early stopping, and cross-validation. It is also essential to be aware of the common cases of overfitting and take steps to prevent it.






{kind=link}